Manage test fixtures for fast and reliable in-memory tests
Why Don’t You Take ‘Given’ in BDD Seriously?
Martin Fowler’s Object Mother Pattern Revisited

Many developers and testers think they are doing behaviour driven development when they use Gherkin tools, such as Cucumber, SpecFlow or BDDfy. But a tool alone does not do the trick. Why do you think the inventors of BDD stopped using Cucumber and Jbehave?
I claim that BDD is not so much about the tools, it is about a way of thinking. In this post, I will focus on one aspect of BDD which I believe the BDD community is not taking seriously enough — the initial context which is declared in one or more Given statements.
The set of one or more Given statements is the key to manage test fixtures for fast and reliable in-memory tests. More than that, my experience over the last several years shows that this is also the key to manage all levels of tests in a test pyramid.
In this post, I will focus mainly on isolated in-memory tests. In a subsequent post, I will climb higher up a test pyramid.
Similar work
I have struggled to find sources which explain how to properly handle initial context. For in-memory, isolated tests developers tend to use a mocking framework, setting up an entirely new set of mocks for each and every test. For end-to-end integration tests, it’s common to have a test environment with a huge test database, possibly containing a washed version of production data.
Why don’t developers understand that there are benefits to having a common set-up across tests? Why don’t testers understand that the initial state of a test is exactly that — initial state for that test, it does not mean that something in the vast database makes this test pass? Why don’t testers and developers understand that they miss a major opportunity for working closely together if at least they use the same concept of initial state?
Despite the lack of sources that directly address this topic, I realize that I am standing on the shoulders of giants. Dan North has suggested that BDD tests should evolve from isolated tests into end-to-end-tests, and Martin Fowler has suggested a common set-up for tests with the Object Mother pattern,
When you write tests in a reasonably sized system, you find you have to create a lot of example data. If I want to test a sick pay calculation on an employee, I need an employee. But this isn’t just a simple object — I’ll need the employee’s marital status, number of dependents, some employment and payroll history. Potentially this can be a lot of objects to create. This set data is generally referred to as the test fixture.
He then goes on to describe how an Object Mother can produce instances and handle the life-cycle of such test fixtures.
I will in the following describe a way to handle test fixtures in automated tests. I will argue that BDD thinking leads us to a way to manage test fixtures with little overhead, and with simple and easily manageable tests.
I will start with a background, in order to set the scene. I will eventually show a sample C# project with sample tests. The full sample project source code with tests is in a public GitHub repository.
But first let’s start with a definition. Martin Fowler called it test fixtures, I usually call it mocks. The most general term is test double, which will cover other variations, such as stubs, fakes etc. In the following, I will call them test fixtures, except when I need a suitable verb or refer to code, in which case I will refer to mocks which mock production code.
Background
There is an example of how to implement the Object Mother pattern in a paper by Peter Schuh and Stephanie Punke. While they make a good case, one quote in the paper troubles me,
[…] for larger applications, no one would want to maintain a tenthousand line utility class
I don’t ever want to make tens of thousands of lines of test fixture code, even for a large application. That would only cause bugs to creep into my test code. And I want my test code to ensure confidence, I don’t want it to be a new source of bugs. Maybe I am not alone with this opinion, maybe this is why this pattern seems to have been all but forgotten? I suppose that most developers simply create their mocks using a mocking framework and never think twice about using an Object Mother instead.
I still think it’s a good pattern because a common set of fixtures across tests will make tests simpler to read. Tests will also be easier to reason about, since a reader does not need to understand unique mocking for each test; once I understand that we have a business object, say a user named John who is an employee who was hired last week, I can use that knowledge when trying to understand the next test. This is in stark contrast to simply creating new mocks on-the-fly for each test, which might be simple to do but will be cumbersome to maintain.
We need a simpler way to set-up an Object Mother, so we don’t spend too much time doing it, introducing bugs along the way.
If you wonder why I am so concerned about what seems to be a small technical detail about unit testing, please bear with me for a little while.
I assure you that once we have properly nailed the life cycle of test fixtures, it can have a profound effect on all levels of tests in a test pyramid. It will even allow us to systematically reason about functional test coverage, not only line or block coverage.
But first let’s try to understand why we would ever need to write tens of thousands of lines of code for the Object Mother.
Even the most entangled legacy system can logically be seen as consisting of a number of subsystems. In the following I will assume that our tests will target such subsystems. This at least limits the number of fixtures needed for the set of tests which target a given subsystem. If you believe that it would be more correct to test the entire integrated system, then watch Integration Tests are a Scam and return to this post when you are convinced.
Next, let’s figure out where in a subsystem to use the fixtures created by our Object Mother. In a pure functional implementation, it would be easy. Since the return value of a pure function only depends on its input, we can simply create and use the fixtures in each test. Having a subsystem with a pure functional core is not entirely science fiction, and it’s a great idea. Alas, most systems are not architected that way — yet
You could even state that having test fixtures at all is a scam. I don’t think it is a scam, but I certainly believe that it is beneficial to limit the number of test fixtures.
Since we don’t have a pure functional core, we cannot simply rely on creating and using our test fixtures directly in each test.
In order to figure out where we can use our test fixtures, we need to decide what code to mock. I will truncate a long discussion here and simply state that external dependencies of the subsystem is what we want to mock. If you mock anything in between you are probably halfway mocking external dependencies which is bad. If you don’t believe me, watch Please don’t Mock me.
So, it seems that we can get away with an Object Mother which provides only a relatively small set of test fixtures which represent external dependencies of a subsystem. But we still want to avoid writing much boilerplate code for each fixture.
The trick to avoiding too much boilerplate code is to accept that the value is the boundary. I can recommend this presentation on the topic. In other words, we are not too concerned about the mechanics that pass data across boundaries, but we are very concerned about the values which pass boundaries. Hence, boundaries are represented by the set of passed values.
Finally, we need to figure out how to plug-in the test fixtures. Since we cannot simply create and use them in each test method we need some magic to do this.
I frankly don’t like our Object Mother to handle the life-cycle of our test fixtures, as it is commonly agreed upon that this is a separate responsibility.
In my mind there is no doubt — the kind of magic we are looking for is dependency injection and the life-cycle of our test fixtures should be handled by a DI container. I can highly recommend Mark Seemann’s book on the topic of dependency injection. Here is what you need to know in the context of this post,
- Dependencies are declared in a composition root.
- Dependencies are injected into constructors.
Here is the trick: Declare whatever external dependency you have in a composition root in your production code, then override declarations which represent external dependencies in your test composition root.
The end result is your submodule with test fixtures mocked-in for its external dependencies.
That’s integration tests, not unit tests, I hear you say. I won’t argue that point, I will just point out that we will have isolated tests, tests which can run in-memory, reliably and fast. The term isolated tests is what many people prefer, rather than unit tests.
While you may prefer to call it an integration test or a unit test, I call it an L0 test, because that’s the lowest level of tests I write, as in level zero. This terminology is heavily inspired by the Microsoft Azure DevOps team’s shift left on testing.
Where is the code?
I call myself a developer and I have not written a single line of code so far. Shame on me, here we go.
But first we need to decide what to test.
The discussion above is valid regardless of the concrete technology stack in question. But in the interest of a concrete example, let’s write a REST API using C# and ASP.NET Core. I will use a simple example similar to the one in the paper mentioned above.
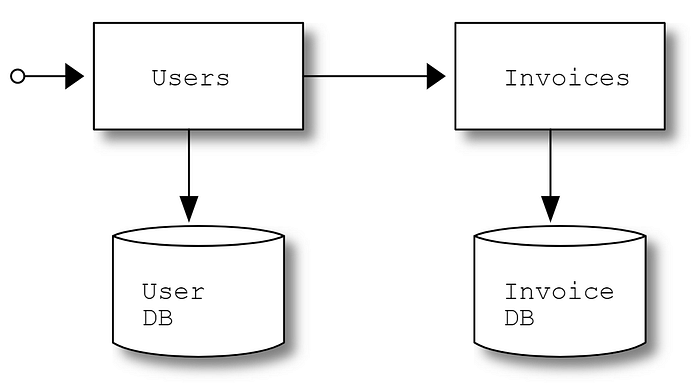
The Users microservice is our subject under test while the Invoices microservice is an external dependency, so the implementation specifics of the Invoices microservice are irrelevant.
In the tests we are about to write, we will also consider the Users microservice’s database to be an external dependency. This allows us to thoroughly test many aspects of database handling code, such as handling of error situations, which can be difficult when you use an actual database.
It is certainly possible to run many of the same tests with an actual database. The tests can still be fast and deterministic with the use of e.g. a dockerized SQL Server or an in-memory EF database. However, this is out of scope for this post.
When we analyze the need for test cases for our Users microservice, we are not really concerned about the technical details of dealing with databases and other microservices. We are only concerned about the data values which are passed as input and across boundaries. If tomorrow we decide to pass data to and from other sources, via Kafka or whatnot, we will keep our reasoning about required functional test coverage and we will keep the tests.
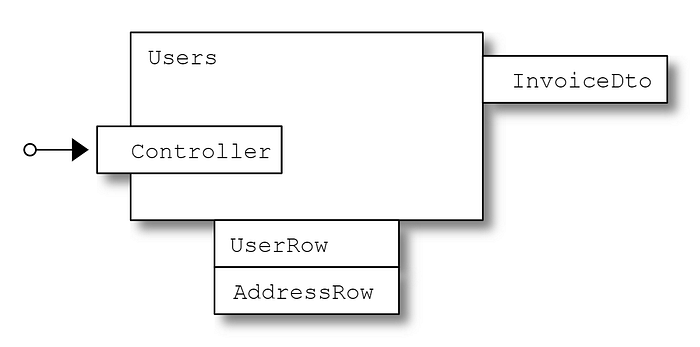
Let’s write a test which gets simple information on a user from our Users microservice. Using the Gherkin language it can be something like the following,
This is not a perfect example. In fact, it is so simple that what you assert in Then is pretty much what you have arranged in Given. In a more advanced example, the data values you arrange in Given would be changed in a less obvious way and asserting on the outcome means asserting that the business logic works as intended. However, for the present discussion, I believe that this example is sufficient.
In my experience, the most important part of the example above is the Given clause. The Given clause is what Dan North called initial state in his original article on BDD. The Given clause declares the context in which the test runs. This is essential in our L0 test as we need to somehow enable our Object Mother to ensure that context. If we are clever about this, we will have a way to do what Dan North predicted in 2006,
As you implement the application, the givens and outcomes are changed to use the actual classes you have implemented, so that by the time the scenario is completed, they have become proper end-to-end functional tests.
But let’s not get ahead of ourselves here. As long as this post may be, it’s but a baby-step towards writing tests which cover the entire test pyramid.
I am a fan of BDD thinking, I’m not a fan of the Gherkin language or commonly used tools which turn Gherkin text into boilerplate code.
Long story short, I worked on a large project in which we practiced Specification by Example. My experience was that even a fairly technical business analyst find it difficult to read Gherkin specifications, and find it utterly impossible to write requirements using Gherkin. Developers and testers can surely implement the different parts of the language (Given, When Then, And) but the result is that the test code is split into many small parts which are difficult to maintain.
I could probably have saved some time by asking Liz Keogh. Here is her opinion on the topic,
The English-language Gherkin syntax is hard to refactor. The tools form another layer of abstraction and maintenance on top of your usual code. There’s a learning curve that comes with them that can be a bit tricky. The only reason to use the tools is because you want to collaborate with non-technical stakeholders. If nobody outside your team is reading your scenarios after automation, then you don’t need them.
In my defence, she wrote what’s quoted above years after I reached the same conclusion.
We decided not to use Gherkin related tools. We deleted our SpecFlow feature files and implemented tests with a simple syntax which essentially captures the Given, When and Then of Gherkin, but also resembles the AAA (Arrange, Act and Assert) commonly used in unit tests.
Without further ado, here is the test from above using this syntax,
There is a lot to say about this snippet of code, but I will keep it brief here. You can see the complete code at GitHub.
The comments give a hint about how the code relates to Gherkin, AAA and Dan North’s original article on BDD. I’m sure that a tool could help translate Gherkin into code like this, but I don’t see the point. My experience so far is that most tests written this way are short and readable without imposing limits for the rare complex cases.
Notice the way I refer to boundary values e.g.,
I prefer to name each value according to traits of the value which is relevant for a test. In the example above, the test depends on the street address and the ID of the associated user, while other aspects of the address value is irrelevant. The actual value may be new’ed up in test code, deserialized from a Json file, or whatever you prefer. What’s important is that the value is descriptive relative to the test in which it is used.
These values can be so complex that it seems like an understatement to call them values. In such cases, you can build-up each value using a builder pattern, as Liz Keogh suggests. This will also clearly show the relevant traits of the value. A test which uses a builder for the UserRow value will then look something like the following,
Or even better, you can reuse production code for complex values.
I worked on a system in which user business objects were central — and complex. Initially, we would find values for tests by observing and recording real-time behaviour into Json files. Those values were great for producing realistic tests and also for checking backwards compatibility, but inconvenient for testing new and changed user related functionality. That changed as soon as we introduced our interpretation of CQRS. Having a command CreateUser in production code allowed us to create the latest incarnation of users in test code. You could say that for these complex objects, the Object Mother was implemented in production code!
If you are accustomed to unit testing REST API controller classes, you may wonder why the target of my test is an HTTP client and not simply the C# controller class. In case you do wonder, I suggest you read Andrew Lock’s post on this topic. It’s not my goal to test Microsoft’s ASP.NET Core middleware, but by including it in the test, the effect can be that I put much more of my own code under test and thus end up with a much more valuable test. It does not have any real impact in this super simple example, but in real-world code it can be essential. In fact, it is so essential that we now follow a principle, that we want to put as much code under test as possible, as long as tests are fast and deterministic.
You will notice that I have multiple assert statements. This is considered bad practice for traditional unit testing, but is commonly accepted in the BDD world. I have written about having multiple asserts in unit tests here and there. In short, a failing assert statement causes a test to stop execution, hence the outcome of subsequent assert statements is unknown. My solution is to let execution stop when it makes no sense to continue but otherwise I execute all assert statements regardless of the outcome of other assert statements.
Getting back to the topic of this post, where in the test code do we interact with the Object Mother? The astute reader will have noticed that we don’t directly interact with the Object Mother as we have introduced a layer of indirection in the form of a context builder.
We also never interact directly with test fixtures, but it is beyond the scope of this post to dig into why this is a sensible principle and how to follow it.
I will later dig into the power we get from the builder, for initial state, state changes etc. across levels of tests. But before we dig into the why, let’s delve into the how — how we feed the Object Mother with enough information that she becomes able to hand out test fixtures.
Here is the implementation of the Invoices microservice mock,
This is how most of my mocks look like these days — handled data is passed-in using a WithData method, and the data is used in methods of mocked interfaces. That’s all, often little more than a couple of lines per mock are needed.
The trick is the IMockForData<> generic interface. We declare each of these to the DI container in the test composition root, specifying that a given implementation of an interface to mock expects to receive data of a given type, similar to the following,
The second line in the above snippet declares that the class MockForDataUsersStorageFacade implements the interface which abstracts our Users database, IUsersStorageFacade, and expects to receive two types of data,
In this simple example, it’s mainly a matter of taste how many interfaces you wish to implement in a single class. But in more complex examples, your choice can potentially make life much easier, and it can make test code much simpler.
Naturally, there are cases in which a mock is not that simple. But a surprisingly large part of mocks contain no logic whatsoever, they have cyclomatic complexity of 1, and thus the risk of introducing bugs in test code is minimal. This approach is as simple as using a mocking framework, but you can still make complex mocks if you have a need for it. The true benefit of this approach over simply using a mocking framework will not be entirely clear until I have described the power of the builder, especially when applied to all levels of tests in a test pyramid. But this post is long enough as it is, so that will be a topic for a later post.
If you are looking for our Object Mother in the above snippets, then you are looking in vain, it’s not there directly.
As I have mentioned before, all life-cycle management has been delegated to the DI container. There is still a little more for an Object Mother to handle — collecting data (actually, initial state of external dependencies) and building test fixtures when requested.
Long story short, the builder is implemented in a small library which we call LeanTest.Net. The source code is on GitHub, it is distributed via nuGet packages. The library contains the context builder mentioned above, which is used by each test to declare initial state. Tests based on LeanTest.Net can run in any test runner (MsTest and Xunit are explicitly supported). The library can be integrated with the DI container you prefer. The example project for this post uses the .NET Core built-in DI container. In other projects we use MS Unity and SimpleInjector. The library is .NET Standard 2.0 so it supports a wide range of legacy as well as modern .NET projects.
The builder uses the DI container to identify test fixtures to build.
It’s that easy — no Object Mother really, just a builder and your preferred DI container.
Conclusion
The concept of an Object Mother, a common source of test fixtures, was born in the context of unit testing and XP.
However, it seems that the concept is valid and important way beyond that context.
To me, it’s about taking Given in BDD seriously. In fact, it’s the secret ingredient which allows us to not think about what functionality to test next but rather think about what behaviour to verify next.
In this post, I have described how to handle test fixtures in a way similar in concept to the Object Mother pattern, but rather different from implementations that I know of.
In our implementation, the Object Mother,
- has been stripped of test fixture life-cycle responsibility, instead it integrates into the DI container of your choice, and
- generically builds test fixtures from boundary values declared to the DI container.
Our implementation is quite different from the original pattern which essentially was a specialized factory pattern.
I have only scratched the surface describing the benefits of this implementation. While the description in this post is little more than a better way to unit test, there is so much more to it.
Did I mention that we have successfully used it on brownfield legacy systems as well as on greenfield, cloud-native systems over the last several years?
Some of the topics that I have not touched are,
- Levels of tests. I have simply claimed that the described approach will work nicely at all levels of tests in a test pyramid. The observant reader will expect that we, inspired by Microsoft, will have L1 and L2 tests in addition to L0 tests. Perhaps even L3 tests.
- Process. I have described the end-result, i.e. how tests should look like and how they should interact with the Object Mother, but I have not described the process for getting there. Is it TDD, and if so — is it inside-out or outside-in TDD, or an integrated adoption of those two approaches? (Spoiler alert — it’s largely like the latter, we strive for continuous testing.)
- Systematic test analysis and documentation of the reasoning behind a set of test cases. I have only hinted at the possibility for visible functional coverage and confidence. (Spoiler alert — it is possible.)
- The role of testers. If developers can write tests at all levels of a test pyramid, do we then still need testers? (Spoiler alert — yes, we still need testers.)
- Using DI. I have described how we use DI in order to handle the life-cycle of test fixtures and also in order to declare and discover boundary values. But there is more to this topic. Using the composition root of production code in tests, then overriding declarations for a few mocks, is core to the approach. In AspNet.Core it’s the key to covering middleware and background jobs, if you use CQRS it’s how you reuse commands and readers from production code.
- Practical experience. We have used the principles described in this post for several years in Saxo Bank, the last few years extensively on our OpenAPI. Our experience is similar to Microsoft’s — we now have faster and more reliable tests which allow us to release with cloud cadence.
I hope it has been as much fun for you to read this post as it was for me to write it. I will consider to write about the so far untouched topics mentioned above if you are interested.
More content at plainenglish.io
Resources
Martin Fowler: ObjectMother.
Peter Schuh and Stephanie Punke: ObjectMother, Easing Test Object Creation in XP.
J B Rainsberger: Integration Tests Are A Scam HD.
Destroy All Software: Functional core, Imperative Shell.
Matt Diephouse: Test Doubles Are A Scam.
Justin Searls: Please don’t mock me.
Destroy All Software: Boundaries.
Mark Seemann: Composition Root.
Monty Python: Let’s not bicker and argue about who killed who.
Microsoft: Shift Left to Make Testing Fast and Reliable.
Dan North: Behavior Modification.
Brian Elgaard: Sample code for this post.
Wikipedia: Command–query separation.
Andrew Lock: Should you unit-test API/MVC controllers in ASP.NET Core?
Brian Elgaard: Multiple Asserts in a Single Unit Test method.
Brian Elgaard: Even More Asserts in a Single Unit Test Method.
Wikipedia: Cyclomatic complexity.
LeanTest.Net: Lean Testing in C#.
LeanTest.Net: Leantest source.
LeanTest.Net: nuGet Packages.
Doug Klugh: London vs Chicago.
Saxo Bank OpenAPI Developer Portal.
Liz Keogh: Scenarios using custom DSLs.

